
The latest updates as of 1/27/2025
How DeepSeek AI Sparked a $600bn NVIDIA Sell-Off – and What it Means for AI’s future
The AI world is buzzing today with the news of DeepSeek AI, a groundbreaking new model out of China that’s making waves in how AI systems are trained. But beyond the technology itself, the financial world is reeling—NVIDIA, a cornerstone of the AI hardware market, saw a $600 billion wipeout in market cap, with the NASDAQ tumbling 3.6%.
Why did NVIDIA, a company essential to the AI boom, suffer such a dramatic reaction? Let’s break down what’s happening with DeepSeek AI, the innovation it represents, and why markets are reacting so strongly.
DeepSeek AI: What Makes It Different?
DeepSeek AI (r1) isn’t just another large AI model. Its training process is fundamentally different from previous approaches:
1. Reinforcement Learning with Self-Generated Tasks:•DeepSeek doesn’t rely on manually curated datasets for its fine-tuning. Instead, it uses reinforcement learning (RL) to generate its own training tasks.•For example, the model might be tasked with solving an equation, thinking step by step. An evaluation function checks:•Was the solution correct?•Was the reasoning clear and understandable?If both criteria are met, the solution is used to further train the model.
2. Strengths& Weaknesses:This approach enables DeepSeek to excel in reasoning tasks like math problems, logical puzzles, or any area where outcomes can be objectively validated.However, it doesn’t offer significant improvements in knowledge-based or intuitive tasks (e.g., creativity or humor).
3. Breaking the Data Barrier:Traditional AI training is limited by the availability of high-quality human-curated data.DeepSeek shifts the bottleneck: we’re no longer data-limited, but compute-limited. This means AI models can be trained longer and more efficiently, as long as you have the computational power.This is a paradigm shift for the AI industry.
The ability to self-generate tasks opens the door to scalable training for areas like mathematics, coding, or scientific reasoning- tasks where results are easy to verify.
Why Did NVIDIA’s Stock Drop?
Despite this being a technological leap forward, the stock market’s reaction has been swift and brutal for NVIDIA. Here’s why:
1. Perceived Reduction in GPU Demand
The claim that AI training is now “compute-bound” might sound like good news for NVIDIA, which dominates the GPU market. However, investors may interpret this differently:
- The shift away from massive human-curated datasets could reduce the overall cost and intensity of AI training.
- If companies can achieve better results with fewer GPUs or extend the lifecycle of their current infrastructure, NVIDIA’s explosive growth could slow.
This perceived reduction in future demand likely fueled the selloff.
2. Increased Competition
DeepSeek’s RL-based training methods might lower barriers to entry for AI development. Smaller companies with enough compute resources—but less access to curated data—could now compete with giants like OpenAI or Google.
- If this technology is as replicable as it seems, it could decentralize AI innovation and reduce reliance on NVIDIA-powered infrastructure.
- This marks a significant step in the democratization of AI, enabling more players—big or small—to contribute to advancements without being constrained by the costs of massive datasets or high-end GPUs.
3. China’s Growing Influence in AI
DeepSeek AI’s Chinese origin might have added geopolitical weight to the market reaction:
- China’s growing dominance in AI threatens the competitive advantage of U.S.-based tech companies.
- If Chinese companies can train advanced models without NVIDIA’s GPUs (or develop competitive alternatives), NVIDIA could lose market share.
- Export restrictions or further trade tensions could further squeeze NVIDIA’s revenue in one of its largest markets.
4. Profit-Taking and Overreaction
NVIDIA’s valuation has soared in recent years, driven by the AI boom. Stocks priced for perfection are especially vulnerable to bad news—or even the perception of it. This news likely served as a trigger for profit-taking by hedge funds and institutional investors.
Additionally, algorithmic trading and momentum-based selling likely amplified the drop, turning negative sentiment into a $600 billion rout.
5. Misunderstanding the Long-Term Impact
While the stock drop reflects short-term fear, the reality might not be so dire for NVIDIA:
- Compute demand could actually increase as reinforcement learning requires longer, iterative training runs.
- Inference workloads (running models in production) are growing exponentially and still rely heavily on GPUs.
- DeepSeek’s success underscores the rapid expansion of AI, which ultimately benefits hardware providers like NVIDIA.
What This Means for the Future of AI
1. AI Development Is Accelerating
Self-generated RL tasks remove the bottleneck of human-labeled data, allowing faster and more scalable training. This could lead to a surge in innovation, especially in areas like science, medicine, and engineering.
2. Smaller Players Could Disrupt the Market
With data no longer being the limiting factor, compute capacity becomes the main differentiator. This levels the playing field, enabling smaller organizations with access to cloud resources to develop competitive models.
The democratization of AI development could lead to an explosion of new ideas and solutions, fundamentally reshaping the landscape of the industry.
3. Ethical and Quality Concerns
While self-generated tasks are efficient, they rely on the model’s ability to evaluate itself. If the evaluation functions are flawed or incomplete, biases and errors could be magnified in unexpected ways.
Closing Thoughts: NVIDIA’s Role in a Shifting Landscape
The market reaction to DeepSeek AI’s debut is a classic case of overcorrection. While the model’s approach represents a shift in AI training, NVIDIA’s role in the ecosystem is far from obsolete. The reality is that demand for GPUs will likely continue to grow as AI applications expand.
In the long term, this news highlights the competitive nature of the AI industry and the speed at which innovation is happening. NVIDIA’s fall may just be the beginning of a broader shift in how we think about AI training, compute infrastructure, and global competition in the space.
One thing is certain: AI development is no longer just about who has the most data—it’s about who can train smarter and faster. This shift, combined with the democratization of AI, marks the beginning of a more inclusive and innovative era in the AI revolution.
Disclaimer: This post is for informational purposes only and should not be considered financial advice.
ChatGPT Talks Better , Deep Seek Codes
DeepSeek V3 represents a significant advancement in open-source large language models, featuring a massive 600-billion parameter architecture trained on 14.8 trillion tokens. As the latest iteration in the DeepSeek family, this model stands out for its exceptional performance in technical and coding tasks while maintaining strong capabilities across general language understanding.
At its core, DeepSeek V3 is designed with a focus on technical excellence and practical deployment flexibility. The model’s architecture leverages state-of-the-art training techniques and optimization methods, enabling it to handle complex programming challenges, technical documentation, and mathematical reasoning with remarkable accuracy. Its open-weight nature allows organizations and researchers to customize and fine-tune the model for specific use cases, making it particularly valuable for specialized technical applications and research projects.
What sets DeepSeek V3 apart is its cost-effective approach to AI deployment. The model achieves high performance while requiring fewer computational resources compared to similar-sized models, making it an attractive option for organizations looking to balance capability with operational efficiency. Its strong multilingual capabilities and superior performance in code-related tasks make it especially useful for global development teams and technical organizations.
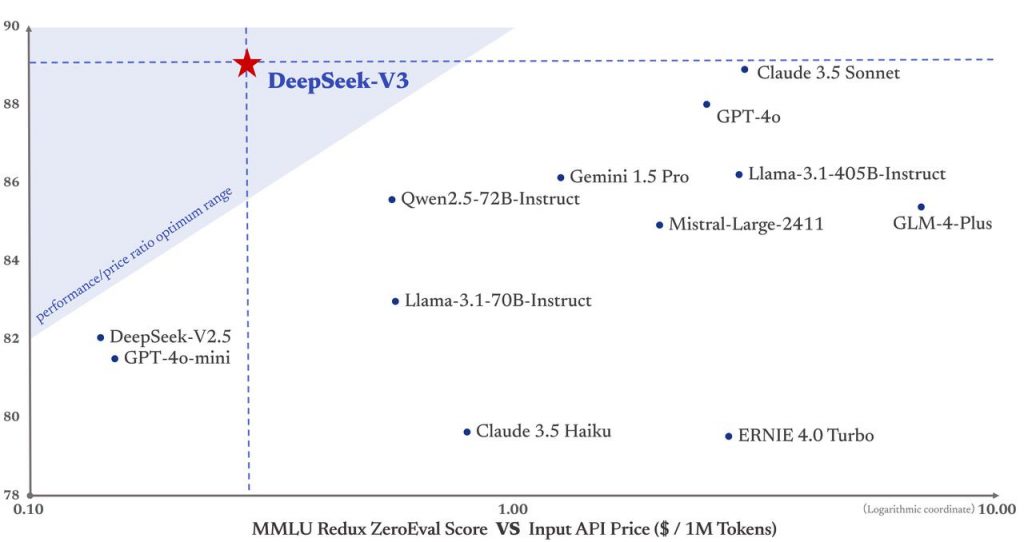
The model excels in several key areas:
-
- Advanced algorithm implementation and optimization
-
- Technical documentation and analysis
-
- Step-by-step logical reasoning
-
- Code generation and debugging
-
- Complex problem-solving in technical domains
For organizations and developers, DeepSeek V3 offers a powerful combination of technical prowess and practical usability. Whether it’s being used for research projects, custom AI development, or specialized technical applications, the model provides the flexibility and performance needed to tackle complex computational challenges while maintaining cost-effectiveness and deployment efficiency.
The Power of Smart Architecture
DeepSeek-V3 represents a fascinating approach to language model design, utilizing a Mixture-of-Experts (MoE) architecture that contains 671B total parameters but only activates 37B for each token. This clever design choice allows the model to maintain high performance while significantly reducing computational costs compared to traditional dense models.
What sets it apart is its innovative load balancing strategy that doesn’t require auxiliary loss functions, along with a multi-token prediction capability that enhances both performance and inference speed. These architectural choices demonstrate how thoughtful design can lead to better efficiency without sacrificing capability.
Performance That Speaks for Itself
The numbers tell an impressive story. DeepSeek-V3 has achieved remarkable results across a wide range of benchmarks:
-
- Strong performance in mathematical reasoning with 89.3% accuracy on GSM8K
-
- Exceptional coding capabilities with 65.2% pass rate on HumanEval
-
- Impressive multilingual abilities with 79.4% accuracy on non-English MMMLU
-
- Strong showing in general knowledge with 87.1% accuracy on MMLU
Perhaps most notably, these results put DeepSeek-V3 in competition with leading closed-source models while maintaining an open-source approach that benefits the entire AI community.
Training Innovation
One of the most remarkable aspects of DeepSeek-V3 is its training efficiency. The model completed pre-training on 14.8 trillion tokens using only 2.788M H800 GPU hours – a testament to its optimized architecture and training approach. This efficiency was achieved through:
-
- Implementation of FP8 mixed precision training
-
- Optimized cross-node communication for MoE training
-
- Stable training process without any irrecoverable loss spikes
Practical Applications
DeepSeek-V3 isn’t just a research breakthrough – it’s designed for practical use. The model offers:
-
- 128K context length for handling long documents
-
- Multiple deployment options through frameworks like SGLang, LMDeploy, and TensorRT-LLM
-
- Support for both NVIDIA and AMD GPUs
-
- Commercial usage rights under its license
The Future of AI Efficiency
What makes DeepSeek-V3 particularly interesting is how it points toward a future where AI models can be both powerful and efficient. Its success demonstrates that through clever architecture choices and optimization, we can build models that rival the largest AI systems while using resources more efficiently.
Getting Started
For those interested in trying DeepSeek-V3, there are several ways to access it:
-
- Through the official chat website at chat.deepseek.com
-
- Via API access at platform.deepseek.com
-
- By running it locally using various open-source frameworks
-
- Through cloud deployment options
-
- Code can be found at https://github.com/deepseek-ai/DeepSeek-V3
The model supports both FP8 and BF16 precision, offering flexibility for different use cases and hardware configurations.
Conclusion
DeepSeek-V3 represents a significant step forward in the development of efficient, powerful language models. Its combination of strong performance, efficient architecture, and practical deployability makes it a compelling option for both researchers and practitioners in the AI field. As we continue to see advances in AI technology, approaches like those demonstrated by DeepSeek-V3 will likely play an increasingly important role in shaping the future of artificial intelligence.
