
Recommendation engines are the unsung heroes shaping our online world. Behind the scenes, these AI systems analyze our behavior to decipher our tastes and interests. Then, with a bit of predictive magic, they surface personalized suggestions to keep us engaged.Whether it’s the next TV show to binge or a new pair of shoes, recommendation systems are master matchmakers between our preferences and products. But how do they work their magic? Let’s peek inside the method behind the machine learning madness.It Starts With Collecting Data
Like any machine learning system, recommendation engines need lots of data to uncover patterns. By tracking our searches, clicks, purchases, likes, ratings and more, tech companies build rich user profiles. This activity data fuels the core algorithms.Finding Connections Through Collaborative Filtering.The most widely used technique is collaborative filtering, which finds similarities between users and items. Users who watched the same shows or bought similar items are clustered together. From these patterns, the system predicts which new shows or items you may enjoy based on your “taste tribe.”
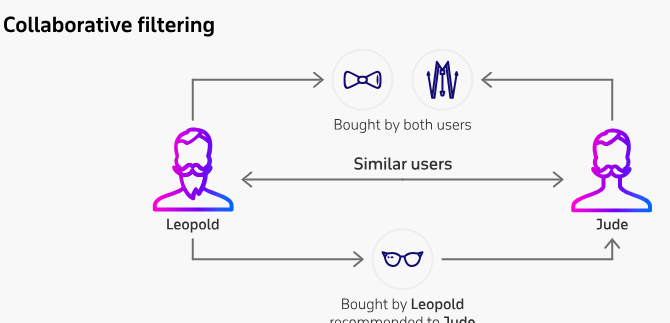
Collaborative filtering is one of the most widely used techniques for generating personalized recommendations. It works by analyzing patterns of user behavior and finding connections between users with similar tastes or preferences. The main steps are:
- Collect user data – Track and store all user interactions like searches, clicks, purchases, ratings, likes etc.
- Identify similar users – Analyze the data to find a “neighborhood” of users who have exhibited similar activity patterns. This defines the user’s taste tribe.
- Make predictions – Use the observed preferences of similar users to predict what items or products the current user may be interested in.
- Recommend top picks – Suggest new items that most closely match the interests of the user’s taste tribe. The more overlap, the better the recommendation.
- Update with feedback – Use the user’s new interactions and feedback on recommendations to refine the user’s profile and search for a better peer group.
Key advantages of collaborative filtering are that it is based entirely on user behavior rather than content analysis. It can recommend complex items like movies without requiring complex item attributes. It also reflects changing interests over time. A limitation is it depends on users having common taste tribes.
In summary, collaborative filtering mines patterns of crowdsourced user data to generate personalized recommendations tailored to observed preferences.
Getting Specific Through Content-Based Filtering
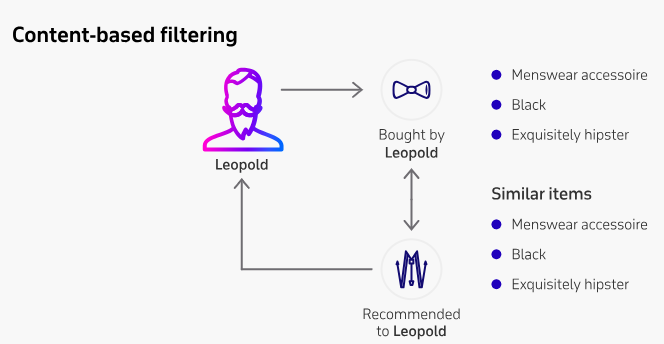
Another approach analyzes the content itself – keywords, topics, genres, styles. It matches attributes of items you’ve liked to recommend similar content. For example, if you liked other abstract paintings, you may enjoy a newly listed abstract work.
Hybrid Methods For Balanced Suggestions
Many recommendation systems combine collaborative and content-based filtering to get the best of both worlds. They’ll analyze your connections and the item content to make nuanced suggestions tailored to multiple factors.
Constantly Updating The Formula
Recommendation algorithms continuously adapt based on new data. Your feedback and activity patterns update your profile. As your tastes change, so do the suggestions to reflect your evolving interests.Next time you get hooked by a recommended video or discover your new favorite boutique, you’ll know there’s some sophisticated AI magic working behind the scenes!
steps to generate a machine learning model for a recommendations system using collaborative filtering:
- Collect user interaction data
- User ID, item ID, interaction type (view, purchase, rating etc)
- Gather as much user activity data as possible
- Clean and preprocess data
- Handle missing values
- Normalize ratings/interactions to common scale
- Split into train and test sets
- Create user-item matrix
- Matrix rows are users and columns are items
- Cells contain interaction data like ratings or binary for interaction
- Apply dimensionality reduction
- Use matrix factorization techniques like SVD to reduce dimensions
- Results in low-dimensional user and item latent factor matrices
- Generate recommendations
- Use cosine similarity between user and item latent features to find closest matches
- Rank items based on similarity scores
- Tune and optimize model
- Adjust factors like number of latent dimensions, loss functions
- Evaluate models on test set with metrics like precision, recall
- Launch and monitor model
- Serve top-N recommendations to users through API
- Log user responses to recreate interaction matrix
- Retrain model periodically with new data
The key aspects are applying matrix factorization to find latent features that capture the relationships between users and items. The closest item matches represent personalized recommendations.
Load libraries
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.feature_extraction.text import TfidfVectorizer
Load dataset
df = pd.read_csv(‘dataset.csv’)
Vectorize text data
tfidf = TfidfVectorizer()
vectorized_data = tfidf.fit_transform(df[‘Content’].values.astype(‘U’))
Compute cosine similarity matrix
similarity = cosine_similarity(vectorized_data)
Map item indices to titles
indices = pd.Series(df.index, index=df[‘Title’]).drop_duplicates()
Function to get recommendations
def get_recommendations(title, similarity=similarity):
idx = indices[title]
scores = list(enumerate(similarity[idx]))
sorted_scores = sorted(scores, key=lambda x: x[1], reverse=True)
sorted_indices = [i[0] for i in sorted_scores]
return df[‘Title’].iloc[sorted_indices].values.tolist()
Get recommendations for a sample item
print(get_recommendations(‘Harry Potter’))
Here is some sample code to create a basic REST API to make a machine learning model available at a public URL using Python and Flask:
from flask import Flask, request, jsonify
import pickle
app = Flask(__name__)
# Load pre-trained model
model = pickle.load(open('model.pkl', 'rb'))
# Define predict function
@app.route('/predict', methods=['POST'])
def predict():
# Get data from request
data = request.get_json(force=True)
# Make prediction using model
prediction = model.predict([data['features']])
# Return JSON response
output = {'prediction': prediction[0]}
return jsonify(output)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=9696)To use this API:
- Save the pretrained model as a .pkl file
- Run the API script
- Make a POST request to the /predict endpoint with a JSON payload containing the features
- The API will return the prediction in the JSON response
This provides a simple way to deploy a model and make predictions publicly accessible via API calls. Some next steps would be to add authentication, input validation, logging, etc.
Evaluation metrics for recommendation engines
- Recall
- Precision
- RMSE (Root Mean Squared Error)
- Mean Reciprocal Rank
- MAP at k (Mean Average Precision at cutoff k)
- NDCG (Normalized Discounted Cumulative Gain)
Tiktok’s Real-Time Recommendation System
TikTok’s Monolith recommendation algorithm achieved massive growth through optimizations for real-time, scalable recommendations. Through real-time training and inference the recommendations systems model was able to generate time sensitive recommendations derived and tuned by user feedback and carefully crafted for each persona. The innovations in Monolith like collisionless hash tables and real-time training that enabled it to deliver excellent results on large-scale recommendation applications.
- Monolith is designed for real-time, scalable recommendations using optimizations like collisionless embedding tables.
- It enables online training from user feedback for time-sensitive recommendations.
- This differs from traditional deep learning frameworks like PyTorch and TensorFlow.
- Monolith architecture supports high fault-tolerance and trades off reliability for real-time learning.
- Competitors have struggled to replicate TikTok’s success despite similar features. Meta cited TikTok for stagnating growth.
- Researchers proved real-time serving and short synchronization intervals are key for recommendation performance.
- Monolith provides a robust production-scale recommendation system through innovations like embedding tables
Design & Benefits
A recently published public paper presents the design and benefits of Monolith’s real-time architecture for industrial recommendation systems.
- Monolith uses a collisionless hash table for embedding sparse features, avoiding quality issues with hash collisions.
- It employs optimizations like expirable embeddings and frequency filtering to reduce memory footprint.
- Monolith enables online training with minute-level parameter synchronization from training to serving.
- This allows the model to continuously learn from new user feedback in near real-time.
- They designed a streaming architecture and online joiner to integrate batch and online training.
- Experiments showed online training boosts AUC, especially with higher sync frequencies like 30 mins.
- Monolith is robust to periodic PS failures, only losing 1 day’s updates with daily snapshots.
- Real-time learning was more important than high fault tolerance for recommendation quality.
- The innovations in Monolith improved performance over baseline collision hash tables and batch-only training.